
In order to troubleshoot linux boot issues effectively, you must have a good understanding of the different events that take place during the linux boot process and more importantly, at which point during the whole boot process that these events take place at. I have a deep dive article on the boot process which you can find here.
Troubleshooting linux boot issues starts off as a process of elimination. You look at the errors and try to identify at which stage of the boot process the errors originated from. If you do not do this first step correctly, you might end up spending hours/days working on the wrong thing.
Some cloud platforms, like Amazon EC2, do not provide users with the ability to interact with the instance’s virtual console. If your instance fails to boot, you have the following troubleshooting features available from EC2:
- Instance’s Screenshot – a screenshot of what the machine’s console would look like if you were to be interacting with it. This is similar to the screen you get when you are using a virtual machine in VirtualBox. When an instance boots successfully, ideally you should only see a login prompt with minor details of the system.
- Instance’s System Log (Console Logs) – boot logs as you would see them on the virtual machine’s console during boot.
- Instance Status Check – Also known as Instance Reachability Check. This check tests whether your instance’s network interface is reachable using ARP ping (Level 2 network check) and this check will start passing once the networking service inside the instance’s OS is running with correct network configurations. Sometimes bad network configurations can still allow this status check to pass but that’s a special case.
- You will most likely need to use a recovery (aka rescue) instance running in the same Availability Zone in order to fix the boot issues. The process will involve detaching the root volume of your broken instance and then attaching it to the recovery instance as a secondary disk in order to troubleshoot the boot issues on the broken instance.
MBR
The MBR is what enables a disk to be identified as a bootable device. For systems that use MBR partitioning, the MBR is also where the partition table it stored. Any corruption to the MBR will lead to error messages like:
No Bootable Devices FoundBoot Device Not Found
Invalid Partition Table
Operating System not found
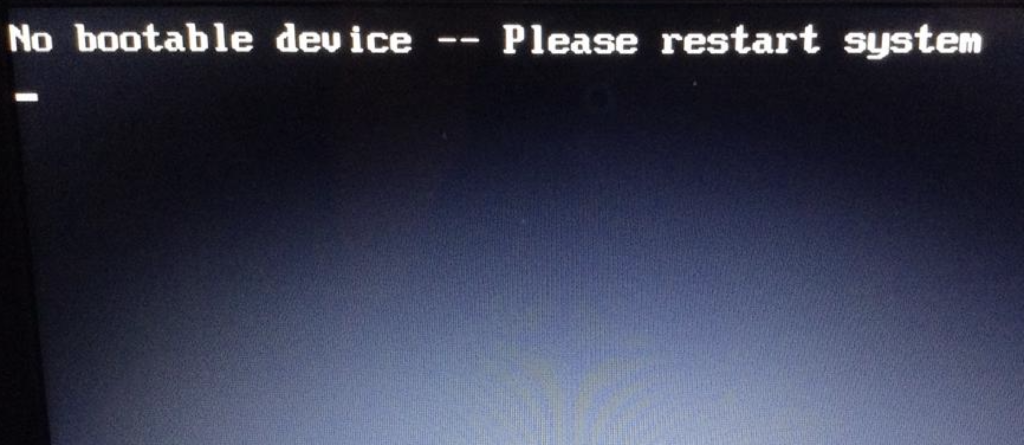
Most errors at the BIOS/MBR stage will be pointing to an issue with the MBR, a bootable device, or partitioning table.
Some disks use the GPT partitioning scheme which means that they technically don’t need an MBR sector. Consider systems that do not use BIOS, like EFI. However, if you plan on using a GPT disk on a system that uses BIOS, the disk will need to have an MBR sector that only exists to allow stage 1 of the bootloader to be executed. You can use gdisk -l /dev/ to verify that a disk has an MBR. Here is the output on a Linux machine using GPT partitioning:
$ gdisk -l /dev/nvme0n1
GPT fdisk (gdisk) version 0.8.10
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Disk /dev/nvme0n1: 16777216 sectors, 8.0 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 66F46060-ED00-4D14-9841-F5CB6310A14A
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 16777182
Partitions will be aligned on 2048-sector boundaries
Total free space is 2014 sectors (1007.0 KiB)
Number Start (sector) End (sector) Size Code Name
1 4096 16777182 8.0 GiB 8300 Linux
128 2048 4095 1024.0 KiB EF02 BIOS Boot Partition
There are also different types of hypervisors on EC2 which can affect how your boot volume should be configured. However, most instance types use an HVM hypervisor that requires an MBR sector on the boot volume.
GRUB
GRUB starts running from the moment stage-1 starts executing and is in control of the system until the linux kernel is loaded. If anything goes wrong during this time, the system will likely drop to a grub rescue prompt, therefore, if you see a grub rescue prompt in the screenshot or console logs, then examples of issues that can lead to this are:
- failed to load stage 1.5 or stage 2 of grub. This could be a result of a corrupted filesystem or bad grub configurations. Grub needs to access “/boot” and “/boot/grub2″ where the kernel image, initramfs and grub configs are stored. Additional grub configurations also exists under “/etc/grub.d” and “/etc/default/grub”
- missing linux kernel image or initramfs. If there are multiple kernels then double-check the version specified in the grub configs and make sure that version exists under /boot.
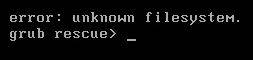
Some GRUB issues can be resolved by making changes directly to the additional configurations (/etc/grub.d and /etc/default/grub). Some times you have to reinstall grub itself, reinstall the kernel or rebuild initramfs based on the error messages you encounter.
Linux boot issues in the MBR and GRUB sections are not very common from my experience since most systems will rarely need to make drastic changes to these areas.
Kernel
The linux kernel performs hardware checks, mounts the root filesystem using initramfs and ends off its section of the boot process by executing the first program init or systemd. If things go wrong during this stage, you will likely be dropped to an emergency shell where initramfs is your filesystem.
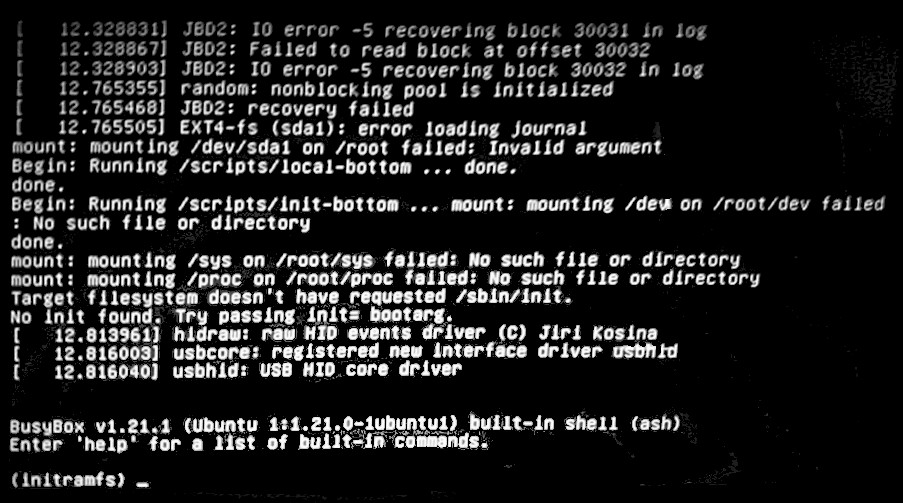
Examples of issues you can come across are:
- Missing or corrupt hardware drivers. Resolving this may be as simple as installing the missing drivers but sometimes you may have to rebuild the kernel and update grub. Grub must be updated any time changes are made to the kernel.
- Failed to mount the root file system. The root filesystem is mounted twice during the boot process. First as read-only by the kernel and then again by init or systemd as read-write when /etc/fstab is processed. Make sure to check grub configuration to make sure the correct label for the root partition is specified. Grub config get it’s information from /etc/fstab so make sure to also check that too.
- The kernel also performs filesystems checks and if they fail, the system can drop to an emergency shell.
init and systemd
Most linux boot issues will likely take place during this stage because system configurations and background services get frequent updates and configuration changes during the lifetime of a system, increasing the chances of breaking the system during boot.
The system manager init or system is responsible for the first set of tasks performed by rc.sysinit script (or equivalent systemd units) and some key tasks involve mounting filesystems, filesystem checks, configuring RAID/LVM and it then starts the background services that run throughout the lifetime of the system. Some key services are OpenSSH, Networking, NTP, rsyslog, SELinux, etc. There are some services that will allow the system to continue booting if they fail to start. However, some issues will cause the system to change to Runlevel 1 (single user mode with minimal functionality) and for systemd it will change to rescue.target (Rescue mode) or emergency.target (Emergency mode).
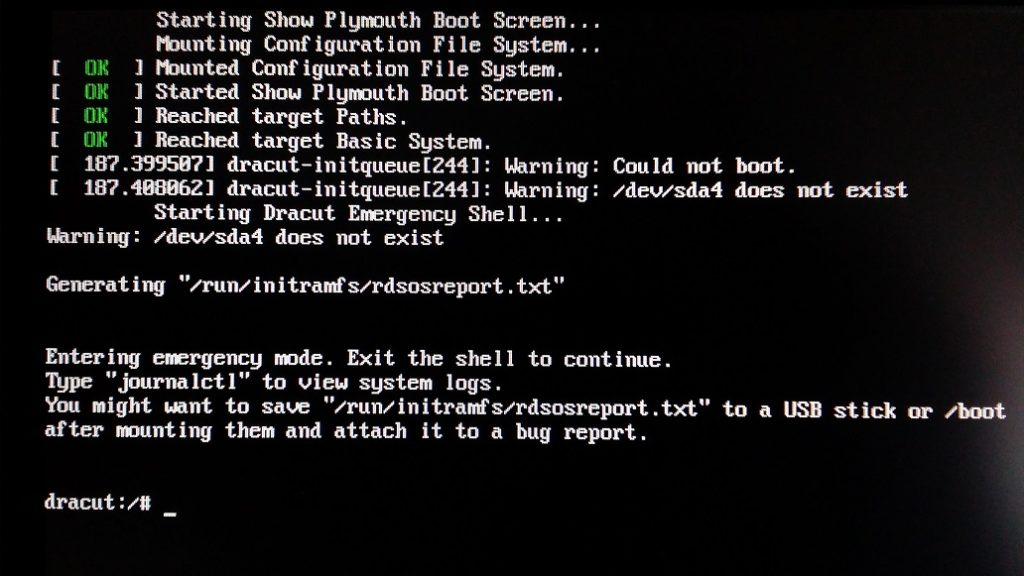
Most issues encountered at this stage are resolved through a recovery instance. Sometimes you may have to use “chroot”. This allows you to change the root filesystem of your recovery instance to use the root filesystem of the broken system. You can perform certain tasks as if you were logged into the broken system itself. Very useful for installing packages, rebuilding the kernel/initramfs images, etc.
Hey Tino I love your content man it’s very well packed. Keep it up. I was wondering if there is anyway I can talk to you on the side like your email address.